RLLib
C++ Template Library to Predict, Control, Learn Behaviors, and Represent Learnable Knowledge using On/Off Policy Reinforcement Learning
RLLib is a lightweight C++ template library that implements incremental, standard, and gradient temporal-difference learning algorithms in Reinforcement Learning. It is an optimized library for robotic applications and embedded devices that operates under fast duty cycles
(e.g., < 30 ms). RLLib has been tested and evaluated on RoboCup 3D soccer simulation agents, physical NAO V4 humanoid robots, and Tiva C series launchpad microcontrollers to predict, control, learn behaviors, and represent learnable knowledge. The implementation of the RLLib library is inspired by the RLPark API, which is a library of temporal-difference learning algorithms written in Java.
RLLib is available from:
Contact: Saminda Abeyruwan ([email protected])
(e.g., < 30 ms). RLLib has been tested and evaluated on RoboCup 3D soccer simulation agents, physical NAO V4 humanoid robots, and Tiva C series launchpad microcontrollers to predict, control, learn behaviors, and represent learnable knowledge. The implementation of the RLLib library is inspired by the RLPark API, which is a library of temporal-difference learning algorithms written in Java.
RLLib is available from:
Contact: Saminda Abeyruwan ([email protected])
Release
The latest release version is v2.2.
Features
- Off-policy prediction algorithms: GTD(lambda), and GQ(lambda),
- Off-policy control algorithms: Greedy-GQ(lambda), Softmax-GQ(lambda), and Off-PAC (can be used in on-policy setting),
- On-policy algorithms:
- TD(lambda), TD(lambda)AlphaBound, and TD(lambda)True.
- Sarsa(lambda), Sarsa(lambda)AlphaBound, Sarsa(lambda)Expected, and Sarsa(lambda)True.
- Actor-Critic (continuous actions, discrete actions, discounted reward settting, averaged reward settings, and so on),
- Supervised learning algorithms: Adaline, IDBD, KI, SemiLinearIDBD, and Autostep,
- Policies: Random, RandomX%Bias, Greedy, Epsilon-greedy, Boltzmann, Normal, and Softmax,
- Dot product: An efficient implementation of the dot product for tile coding based feature representations (with culling traces),
- Benchmarks: Mountain Car, Mountain Car 3D, Swinging Pendulum, Continuous Grid World, Bicycle, Cart Pole, Acrobot, Non-Markov Pole Balancing, and Helicopter environments,
- Optimization: Optimized for very fast duty cycles (e.g., with culling traces, RLLib has been tested on the Robocup 3D simulator agent, and on the NAO V4 (cognition thread)),
- Usage: The algorithm usage is very much similar to RLPark, therefore, swift learning curve,
- Examples: A plethora of examples demonstrating on-policy and off-policy control experiments, and
- Visualization: We provide a Qt4 based application to visualize benchmark problems.
Experimental
On MSP-EXP430G2 LaunchPad, and EK-TM4C123GXL (TivaC) LaunchPad.
Tiva C series launchpad microcontrollers: https://github.com/samindaa/csc688
Tiva C series launchpad microcontrollers: https://github.com/samindaa/csc688
Publication
RLLib has successfully been used in RoboCup 3D soccer simulation; especially for role assignment in formations (Abeyuwan et al.).
Documentation
Demo
|
Off-PAC ContinuousGridworld
|
AverageRewardActorCritic SwingPendulum (Continuous Actions)
|
Usage
RLLib is a C++ template library. The header files are located in the `src` directly. You can simply include this directory from your projects, e.g., `-I./src`, to access the algorithms.
To access the control algorithms:
#include "ControlAlgorithm.h"
To access the predication algorithms:
#include "PredictorAlgorithm"
To access the supervised learning algorithms:
#include "SupervisedAlgorithm.h"
RLLib uses the namespace:
using namespace RLLib
To access the control algorithms:
#include "ControlAlgorithm.h"
To access the predication algorithms:
#include "PredictorAlgorithm"
To access the supervised learning algorithms:
#include "SupervisedAlgorithm.h"
RLLib uses the namespace:
using namespace RLLib
Configuration
The test cases are executed using:
make
./RLLib
- General:
make
./RLLib
- To compile and 32-bit binary on a 64-bit machine:
- Debugging:
Visualization
RLLib provides a QT4.8 based Reinforcement Learning problems and algorithms visualization tool named RLLibViz. Currently RLLibViz visualizes following problems and algorithms:
./configure
./RLLibVizSwingPendulum
./RLLibVizContinuousGridworld
./RLLibVizMountainCar
- On-policy:
- Off-policy:
- In order to run the visualization tool, you need to have QT4.8 installed in your system.
- In order to install RLLibViz:
./configure
./RLLibVizSwingPendulum
./RLLibVizContinuousGridworld
./RLLibVizMountainCar
Testing
RLLib provides a flexible testing framework. Follow these steps to quickly write a test case.
#include "HeaderTest.h"
RLLIB_TEST(YourTest)
class YourTest Test: public YourTestBase
{
public:
YourTestTest() {}
virtual ~Test() {}
void run();
private:
void testYourMethod();
};
void YourTestBase::testYourMethod() {/** Your test code */}
void YourTestBase::run() { testYourMethod(); }
- To access the testing framework: #include "HeaderTest.h"
#include "HeaderTest.h"
RLLIB_TEST(YourTest)
class YourTest Test: public YourTestBase
{
public:
YourTestTest() {}
virtual ~Test() {}
void run();
private:
void testYourMethod();
};
void YourTestBase::testYourMethod() {/** Your test code */}
void YourTestBase::run() { testYourMethod(); }
- Add YourTest to the test/test.cfg file.
- You can use @YourTest to execute only YourTest. For example, if you need to execute only MountainCar test cases, use @MountainCarTest.
Examples
I have evaluated RLLib w.r.t the problems presented in the conference paper: Off-Policy Actor Critic. T. Degris, M. White, R. S. Sutton (2012) In Proceedings of the 29th International Conference on Machine Learning. RLLib's results are very similar to the published results. I have listed some of the results herewith using Matlab.
ContinuousGridWorld
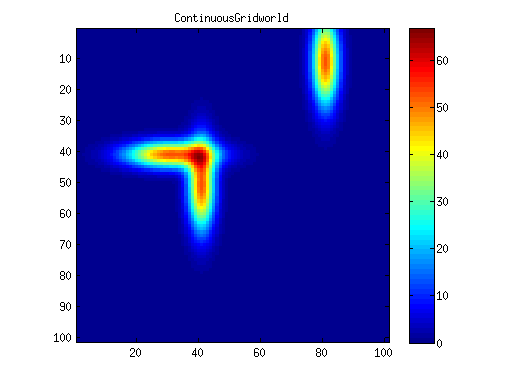
Critic Value Function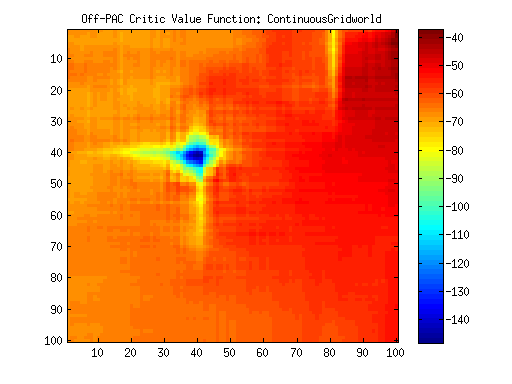
Optimal Policy
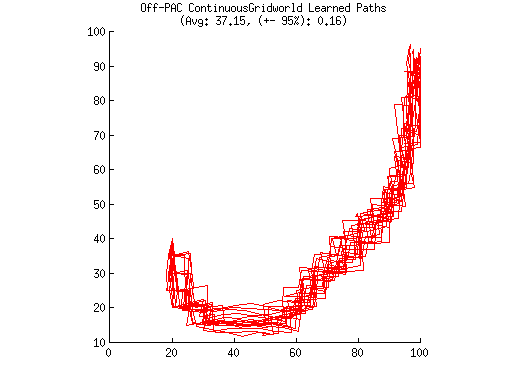
|
Off-PAC SwingPendulumAn optimal policyUniformly Random Behaviour Policy (b)Critic Value Function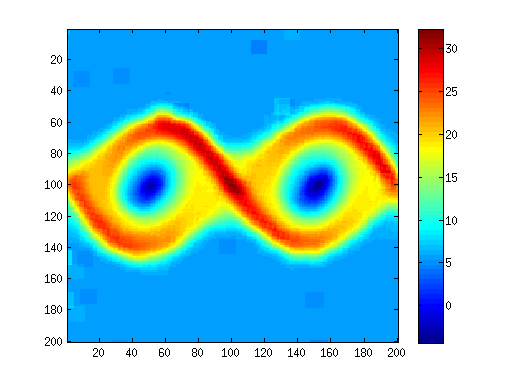
|
Off-PAC Mountain Car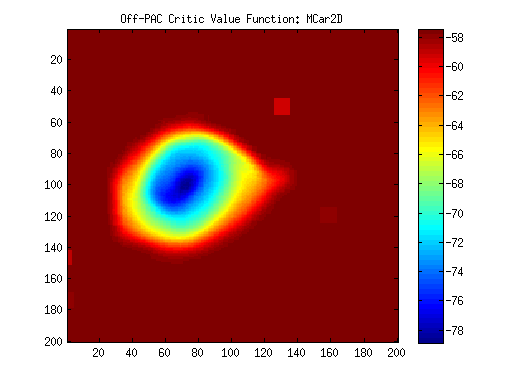
Uniformly Random Behaviour Policy (b)Optimal Policy |
Greedy-GQ Mountain Car 3DA Near Optimal Policy for Random StartsNotes:Mountain Car 3D problem consists of four continuous state variables: {x, y, x_dot, y_dot}. There are five discrete actions, {coast, left, right, down, up}, available in each state. Complete specification of the problem is available in: ExtendedProblemsTest::testGreedyGQMountainCar3D().
|
